
Computer verwandelt Text in Bewegungen
Archivmeldung vom 13.09.2019
Bitte beachten Sie, dass die Meldung den Stand der Dinge zum Zeitpunkt ihrer Veröffentlichung am 13.09.2019 wiedergibt. Eventuelle in der Zwischenzeit veränderte Sachverhalte bleiben daher unberücksichtigt.
Freigeschaltet durch Thorsten Schmitt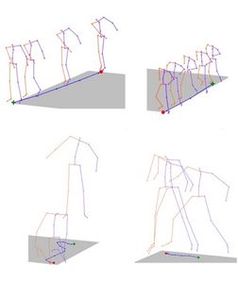
Bild: cmu.edu
Experten der Carnegie Mellon University (CMU) haben ein Computermodell entwickelt, das geschriebene Sprache in physische Animationen verwandelt. Hierfür setzen sie auf ein selbstlernendes neurales System namens "Joint Language-to-Pose" (JL2P). Dieses erkennt in Texten automatisch Passagen, die Bewegungen beschreiben, und "übersetzt" sie in einfache computergenerierte Trickfilme. Mit der Methode ließen sich künftig zum Beispiel Filme einfach direkt aus Drehbüchern generieren.
Auch für Roboter nutzbar
"Die Wissenschaft hat bereits gewaltige Fortschritte gemacht, wenn es darum geht, Computern das Verstehen von natürlicher Sprache beizubringen und realistische Animationen anhand einer Reihe von physischen Posen und Bewegungen zu kreieren", sagt Louis-Philippe Morency, Associate Professor am Language Technologies Institute der CMU. Leider sei es bislang aber noch nicht gelungen, eine Verbindung zwischen der Sprache und den Bewegungen herzustellen. "Mit unserer neuralen Architektur wollen wir diese beiden Welten nun zusammenbringen. Das JL2P-Modell versteht, wie Sprache mit Handlungen, Gesten und Bewegungen zusammenhängt", so der Forscher.
Im Moment befindet sich das Ganze allerdings noch in einem sehr frühen Entwicklungsstadium. "Aus Sicht der Künstlichen Intelligenz und der theoretischen Grundlagen ist das aber schon jetzt äußerst spannend", erklärt Morency. Derzeit drehe sich alles um die Animation virtueller Charaktere. "Die Verbindung von Sprache und Bewegung könnte man aber auch bei Robotern nutzen. Wir könnten beispielsweise einem persönlichen Helfer einfach sagen, was er tun soll. Umgekehrt könnte ein Computer so auch erkennen, was in einem Video zu sehen ist", erläutert der Experte.
Vom Einfachen zum Komplexen
Für die Entwicklung ihres innovativen JL2P-Ansatzes haben die CMU-Wissenschaftler ihrem Computermodell einen strengen Lehrplan verpasst. Dieser beinhaltete zunächst ein ausführliches Studium von kurzen, einfachen Bewegungssequenzen - zum Beispiel eine einzelne Person, die gerade nach vorne geht. Anschließend wurde die Komplexität der Bewegungen kontinuierlich gesteigert, bis auch schwierigere, längere Abläufe richtig erfasst werden konnten.
"Verben und Adverben beschreiben die Bewegung und die Geschwindigkeit beziehungsweise Beschleunigung einer Aktion, während Haupt- und Eigenschaftswörter Rückschlüsse auf Orte und Bewegungsrichtungen erlauben", schildert Projektmitarbeiterin Chaitanya Ahuja die Funktionsweise. "Letztendliches Ziel ist es, komplexe Sequenzen zu animieren, bei denen mehrere Aktionen gleichzeitig oder hintereinander stattfinden."
Quelle: www.pressetext.com/Markus Steiner




